Introduction
Race is a social construct that can be defined in a few ways but generally involves skin color, language, and phenotypic features as major criteria.1 Perspectives on race include racial identity, which refers to self-identification, race reflection, which refers to how one thinks others identify them, and observed race which is how others actually identify them. Race can also overlap with ethnicity, such as with “Hispanic” or “Jewish” groups.1,2
Racism also has several perspectives, but it is generally understood to include not just implicit bias or personal discrimination but also the structure of rules and practices which encourages and fosters such discrimination.1 One definition of structural racism is the “totality of ways in which societies foster racial discrimination through mutually reinforcing systems of housing, education, employment, earnings, benefits, credit, media, health care, and criminal justice”.3 Measuring racism is challenging. Not only can it be subjective, but it can also be politically charged and based on data that is difficult to collect. Nonetheless, it is crucial to have a measurable outcome in order to monitor change and set goals. For this reason, many approaches to measuring racism have emerged, including the Perceived Discrimination Scale.3
Artificial Intelligence (AI) can be defined as “a field of science and engineering concerned with the computational understanding of what is commonly called intelligent behavior, and with the creation of artifacts that exhibit such behavior”.4 It is a quickly growing field used broadly today in and outside the clinical context. One overarching theme of AI is to affect behavior change.5 Some of the areas that AI encompasses are machine learning, deep learning, neural networks, computer vision, natural language processing (NLP), skin imaging, and extensive dataset analysis. Machine learning (ML) is a method of data analysis that builds and improves predictive models automatically. ML is used in the clinical setting to diagnose conditions, predict outcomes, and guide clinical decision-making. NLP is a branch of AI that focuses on making sense of text or voice data using ML as well as other methodologies. It has become particularly prominent in medical AI because a large proportion of clinical data is unstructured, and NLP can help structure, understand, and thus analyze this data.
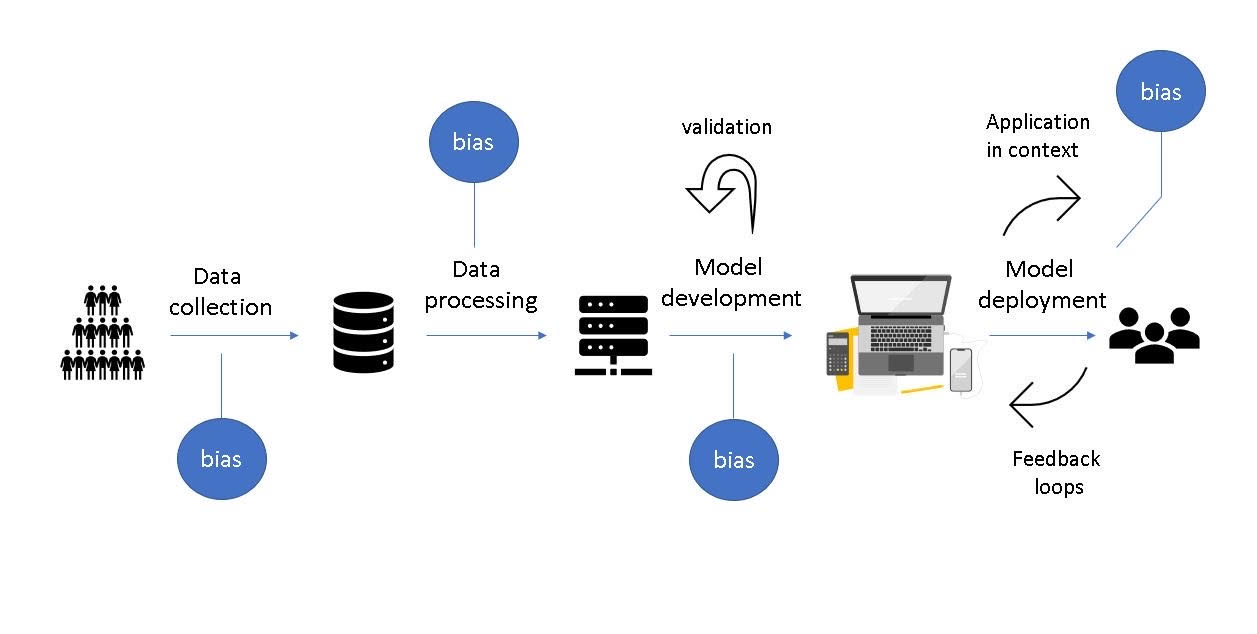
There is promise that AI can help address issues of health inequities and socioeconomic determinants of health. However, there is also a concern and significant research that shows that AI models can exacerbate racial bias. The social costs of inaccurate predictions are substantial, especially as racial divides in the country deepen.1 People tend to evaluate AI as relatively autonomous, similar to other humans.5 This increases blame when AI is wrong to levels similar to that of humans. People tend to blame programmers and companies rather than the algorithms involved.5 This article aims to examine some of the ways in which racial bias gets included in AI and touch upon what can be done to mitigate these biases. Figure 1 outlines the steps involved in developing AI-based systems and the ways bias may be introduced.

Raw Data Can Be Racially Biased
Machine learning starts with raw data harvested from an ever-growing collection of data sources. Electronic health records, administrative health records, data warehouses, social media data,6 as well as population health data are collected and stored with various entities.7 If the raw data available for training and validation is biased, the analytical results will be biased. Raw data can be racially biased in an underrepresentation of minority groups during data collection, favoring racially biased data types, and in racial discrepancy with health information exchange (HIE).
During the COVID-19 pandemic, there was a significant disparity of data collection in minority groups for a few major reasons; African Americans were less likely to be offered COVID-19 testing, less likely to have testing clinics available in their neighborhood, and less likely to be able to follow public health guidelines with their living situation.8 Randomized control trials often have strict inclusion and exclusion criteria which can select for a racially biased study sample. Social media data is inherently biased towards people with consistent internet and mobile platform access or who speak English.6,7 Population databases can underrepresent low- and middle-income individuals due to resource constraints and undocumented immigrants due to safety concerns.
Furthermore, HIE is not robust. Disadvantaged or minority groups can have fewer options for providers leading to a greater need for information exchange between health systems.8 When HIE fails, this can lead to a disproportionately large amount of missing data for minority groups. Data collection and information exchange discrepancies lead to an underrepresentation of data for these groups. When this biased data is used to build models, it limits the generalizability of the model results but not in a way that is easy to identify. In many ways, an inaccurate score might be more harmful than no score.
Machine learning models also tend to favor discrete, structured, physiological data due to the reliability and abundance of this data.9 Excluding socioeconomic information such as income and family status, which are correlated to race, can exacerbate bias by making all data sources look equal. For example, disadvantaged patients may be more likely to present later in their disease, have fewer data collection points (less primacy care visits), or have less ability to follow up with recommended care. This can racially bias models to be more inaccurate in diagnosis or prognosis for these patients.
Data Extraction, Organization, and Model Development Can Be Racially Biased
Raw data is prepared for predictive analytics by extracting, cleaning, organizing, and labeling. Data labeling involves adding meaningful labels to raw data to give context. Labeled data can then be used in model development. In NLP, for example, word embeddings are used to label language. Word embeddings are the algorithmic representation of words such that similar word meanings have similar representations. These embeddings have been shown to be biased, such as how “man” is represented similar to “doctor” and “woman” is represented similar to “nurse”.10 It is not difficult to imagine how embeddings may similarly be racially biased. Language is particularly tricky as it has been used throughout colonization to exclude groups of people and justify social hierarchy and violence. Stereotypes and biases are thus inherent in daily language. In this way, NLP is intricately tied to race. For example, language flagged as offensive can lack interpretation based on racial context.1 NLP implementations can thus build racial bias into their models. In addition, data extractors, cleaners, and organizers themselves can be biased. Anti-racist activists can assign offensive labels differently than other workers, for example. Politically motivated projects can organize differently based on race as well.
After data preparation, manual aspects of model development usually involve decisions on tuning parameters (components used to optimize the model’s accuracy), feature selection (choosing which variables are considered predictive in the model), and performance metrics. Without careful attention and a clear understanding of how these variables affect racial disparities, it can be challenging to account for racially biased models. Blindly choosing features such as race and ethnicity in the model can embed inequities in model results. Even automatic feature selection can be racially biased due to the misleading nature of p-values.11
One classic example is using statistical models to derive equations to estimate kidney function using an estimated glomerular filtration rate (eGFR).12 These models and thus equations use race as a coefficient to predict eGFR. Authors referenced literature that supported Black individuals having higher blood creatinine levels due to increased muscle mass, though that literature was not scientifically robust and has yet to be replicated. Further, several studies have shown that the inclusion of the race or ethnicity coefficient does not improve accuracy among other ethnic or racial groups or Black people outside the USA.12 Despite these studies, these eGFR equations continue to be prevalent in the USA and ultimately classify Black people as having increased kidney function compared to the gold standard. This can disproportionately disqualify Black people from transplant evaluation and have downstream effects on prognostication and appropriate medical care. This example also highlights how predictive algorithms in medicine can quickly be widely adopted without robust external validation and how difficult it can be to change already implemented models.
Implementation of AI Results Can Be Racially Biased
Implementing AI can involve clinical decision support, predictions of patient care and prognosis, analysis of public health data, and distribution of health resources, to name just a few. To look at an example from the legal world, ML is used to inform decisions on every level of law enforcement, including punishment, bond amounts, and rehabilitation as an option. Predictive policing as a concept aims to pre-emptively intervene in people more likely to commit a crime. The ProPublica study looked at arrests using an ML scoring system and found that these scores were highly unreliable. They also found that black defendants were almost twice as likely to get labeled as future criminals even when criminal history, age, and gender were controlled for.13 Of particular interest is that the scoring system studied never asks for the race as raw data. This would suggest that despite excluding race as a discrete variable, there is significant racial disparity in predictions. Racially correlated variables may be responsible for this result.
Predictive algorithms like this could be used in the medical world to make decisions on policing communities during pandemics, such as enforcing quarantine or mask rules. If the models we use are racially biased, this could exacerbate the current racial divide in the US.14 Similar research shows poor accuracy or racial bias for AI in population health,3,6,15,16 dermatology,15 heart failure,16 opioid use,17 kidney function,18 speech recognition,19 gender classification,20 and many others.21 There are very few validations of AI in general.22–24 This continues to be a highly needed area of research today. Externally validated, independent, robust studies aggregated in systematic reviews and clinical practice guidelines are practically non-existent today. Unlike areas of medicine where excellent quality of evidence is available, there is a high risk of widespread adoption before rigorous testing with AI. Further, trainers and end users could use biased and unvalidated model results to create, confirm, or exaggerate personal biases, leading to a perpetuating cycle.
Bias in prognostic predictions, for example, in labeling admitted patients for risk of readmission or decompensation, can lead to discrepancies in disposition or level of care based on those biases. Population-based interventions have also implemented ML, such as vaccine prevalence monitoring, digital contact tracing, and combating anti-vaccine misinformation.6 Social media data is often mined to identify hotspots of communicable disease,6 and racial bias in these identification algorithms can misallocate resources. Diagnostic AI, such as with skin recognition, has also been shown to be biased.15 It is easy to imagine how an algorithm focused on clinical decision support for a dermatological disease might worsen health disparity. For example, if the prediction algorithm is trained with a predominantly Caucasian population in diagnosing skin cancer, it could lead to poor accuracy in Black or Brown populations.15 In this case, skin cancer could be under-identified and undertreated in dark-skinned populations, worsening already existing medical discrepancies.
Improving Racial Bias
The solution to these problems is not straightforward. It is challenging to simply ignore race because variables otherwise well-correlated to race may still encode racial disparity in the prediction.25 Even if one endeavors to ignore race in a more sophisticated way and somehow erases any correlation to race in the data, this ignores the issue. In this way, current racial inequity is reproduced. Attempting to inject fairness by rebalancing data can introduce even more issues of inaccuracy or create equality when it does not exist. Another barrier is that there is little incentive to improve models for racial reasons, especially in the private sector.25
Nonetheless, improvements can be made. Reducing the underrepresentation of racial minorities can be improved by directly involving these groups in data participation. Partnering with racially diverse organizations like Black in AI, Data for Black Lives, and the Algorithmic Justice League can help as well.1 Reducing barriers to testing can improve data collection as well.
Improving data transparency, increasing external validation by independent sources before widespread implementation, and strengthening data governance can significantly increase trust and reduce model bias.8,25 Improving model selection can help, too, as some models are fairer than others. For example, linear support vector machine models produce fairer predictions without compromising accuracy.6 Alongside process improvements in data collection, labeling, and modeling, comprehensive interdisciplinary racial training for designers and users in each model creation step is needed to address these issues.26
Conclusion
AI can be racially biased in many ways. Every step of the machine learning process, including raw data collection and processing, data labeling, model building, validation, and implementation, is prone to racial bias. It is essential to acknowledge that even erasing any correlation to race in raw or processed data will reproduce racial inequity. It can be daunting to challenge and improve this bias as significant improvement requires interdisciplinary and extensive training for builders, trainers, and end users. Nevertheless, several steps can be taken in data collection, model building, and the implementation process to reduce racial bias. By addressing these issues now, we can mitigate an exacerbation of racial divides due to AI and maybe even start to bridge some of these gaps and improve racial equity.
Disclosures/Conflicts of Interest
The author has no conflicts of interest to disclose.
Corresponding author
Atin Jindal, MD
Assistant Professor of Medicine, Clinical Educator
The Warren Alpert Medical School of Brown University
Academic Hospitalist, Physician Informatics Liaison
Division of Hospital Medicine, The Miriam Hospital
Providence, RI, 02906
Email: AJindal@lifespan.org